
データウェアハウスでは、構造化データを整理統合します。
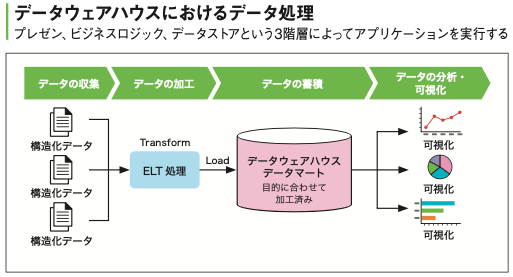
データウェアハウスとは、意思決定支援に向けてデータを分析するため、利用しやすい形に加工したデータを蓄積したデータベースです。
既存のデータベースに蓄積された構造化データは、ETLツールによって、抽出(Extract)、変換(Transform、ロード(Load)されます。
その上で、データを整理統合することでデータウェアハウスを構築するのです。
データレイクでは、非構造化データも整理統合します。
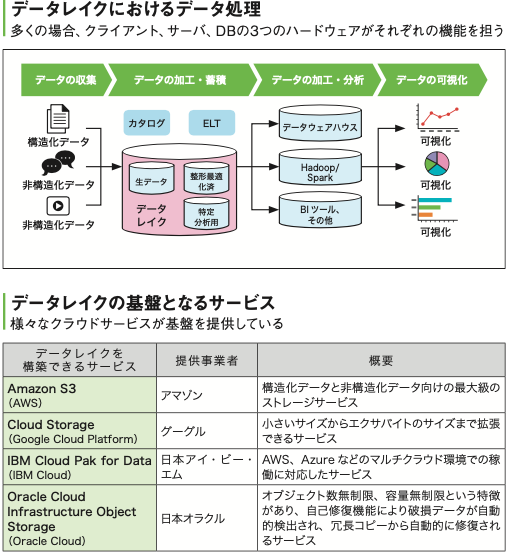
一方、データレイクとは構造化データだけでなく、多種多様な非構造化データも、未加工もしくは最小限の加工で一元管理するストレージリポジトリです。
データレイクが必要になった背景には、データ量の圧倒的な増加、蓄積するデータの多様化、利用ニーズの多様化、そしてビッグデータ・AI技術の進展があります。
データレイクには、一元的な管理・蓄積機能だけでなく、柔軟な処理機能、標準的なデータアクセス機能も求められます。
アマゾンやグーグルなどの主要クラウドベンダーは、Amazon S3、Cloud Storageなど、データレイクの基盤となるサービスを提供しています。









